一、环境
生产服务器有600台左右,有 ubuntu 和 centos 两种系统。zabbix 部署在 VMware ESXi 中,配置为8核16G。
二、zabbix-server 部署
zabbix 使用 4.4.10,mysql 使用 5.7.28。部署过程略。
rpm -vih https://repo.zabbix.com/zabbix/4.4/rhel/7/x86_64/zabbix-release-4.4-1.el7.noarch.rpm
三、自动发现
Zabbix提供了高效灵活的网络自动发现功能,通过这种方式无需在服务器上进行手动配置便可直接启动对新 host 的监控。网络发现由两个阶段组成:发现和动作。
zabbix 定期扫描网络发现规则中定义的IP范围,并为每条规则单独配置了检测的频率。请注意,一条发现规则始终由一个发现进程处理,IP范围不会在多个发现进程之间分割(所以慢)。觉得慢可以用自动注册,这个是非常快的。
1、前端配置
配置 zabbix 的网络发现规则来发现主机和服务:
• 首先进入 配置 → 自动发现
• 单击 创建发现规则(Create rule) (或在自动发现规则名称上编辑现有规则)
• 编辑自动发现规则属性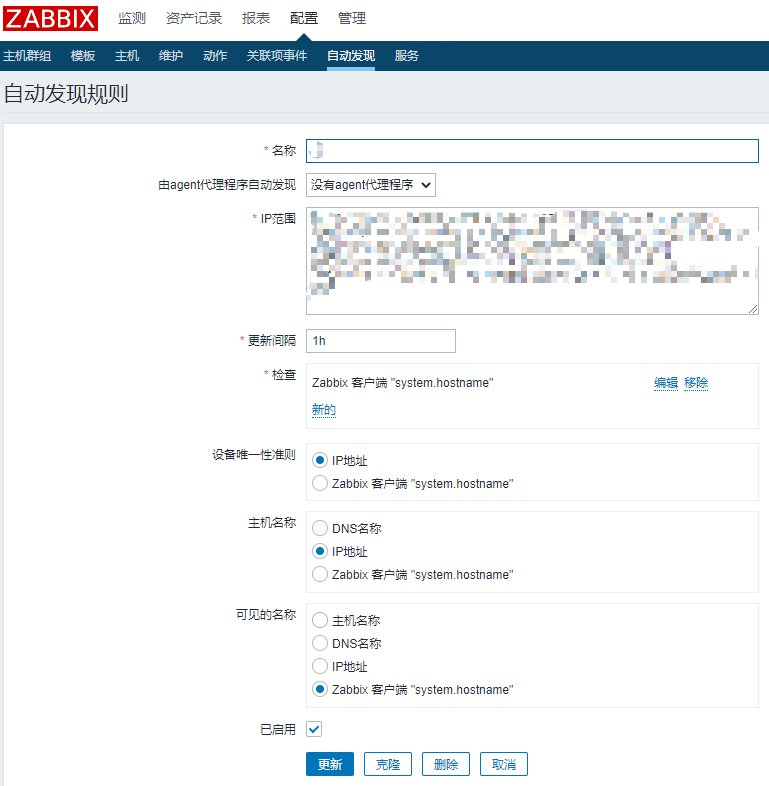
当 zabbix 发现符合条件的 agent,它会调用动作将所发现的 Linux 服务器添加到相应的组并链接模板。所以必须要定义事件源为“自动发现”的动作。
在 zabbix 前端页面,点击配置 → 动作,选择自动发现为事件源,然后单击创建动作:
• 在动作选项卡,定义动作名称。
• 可选指定条件。接收到的值为"system.hostname"
• 在“操作”选项卡中,需要添加关联操作,如“添加到主机组”,“链接到模板”等。
2、agent 配置
agent 配置会由下一部分 ansible 批量完成。
这是实际环境中一台agent的配置:
root@xxxxx:~# sed -r '/^$|^#/d' /etc/zabbix/zabbix_agentd.conf
PidFile=/run/zabbix/zabbix_agentd.pid
LogFile=/var/log/zabbix/zabbix_agentd.log
LogFileSize=0
Server=10.202.216.20
Include=/etc/zabbix/zabbix_agentd.d/*.conf
HostMetadataItem=system.uname
Timeout=20
五、zabbix-agent 部署
zabbix-agent 采用 ansible 批量部署到被监控主机。
[root@zabbix ansible]# cat ansible.cfg
[defaults]
inventory = ./hosts
log_path = /var/log/ansible.log
host_key_checking = False
deprecation_warnings=False
forks=100
# 主机清单采用这种格式:
[root@zabbix ansible]# cat hosts
[test]
10.0.0.1
10.0.0.2
[test:vars]
ansible_ssh_port=22
ansinle_ssh_user=root
ansible_ssh_pass='000000'playbook 内容(采用 role 方式):
[root@zabbix ansible]# tree roles/zabbix-agent/
roles/zabbix-agent/
├── files
│ ├── zabbix-agent-4.4.10-1.el7.x86_64.rpm
│ ├── zabbix-agent_4.4.10-1+focal_amd64.deb
│ └── zabbix-agent.sh
└── tasks
└── main.yaml
2 directories, 5 files
[root@zabbix ansible]# cat roles/zabbix-agent/tasks/main.yaml
- name: create zabbix related file directory
file:
path: /usr/local/zabbix_files
state: directory
- name: push zabbix-agent
copy:
src: "{{ item }}"
dest: /usr/local/zabbix_files
with_items:
- "zabbix-agent-4.4.10-1.el7.x86_64.rpm"
- "zabbix-agent_4.4.10-1+focal_amd64.deb"
- name: deploy zabbix-agent
script: zabbix-agent.sh
- name: start zabbix-agent
systemd:
name: zabbix-agent
state: restarted
enabled: yes
- name: create zabbix-agent scripts directory
file:
path: /etc/zabbix/scripts/
state: directory
[root@zabbix ansible]# cat site.yaml
- hosts: all
remote_user: root
gather_facts: false
roles:
- role: zabbix-agent
tags: t1
- role: nvme-discovery
tags: t2
- role: nvidia-driver-survival
tags: t2
- role: nvidia-gpu-discovery
tags: t2
- role: lotus-alive-state
tags: t3
- role: xsky-cluster-space
tags: t4脚本内容,zabbix-agent.sh:
注:ip 获取方式请根据实际情况来,自动发现就无所谓,反正用不上。自动注册就需要注意了,其实建议ip地址从主机清单中获取,那就需要使用 template 和内置变量 {{inventory_hostname}}。
#!/bin/bash
Zabbix_Server_IP='10.202.216.20'
#Zabbix_Agent_IP=$(ip a | grep 'inet ' | grep -v 127.0.0.1 | awk '{print $2}' | cut -f1 -d '/' | head -n1)
function configure (){
sed -i '/^Server=/c Server='${Zabbix_Server_IP}'' /etc/zabbix/zabbix_agentd.conf
sed -i '/^ServerActive=/c ServerActive='${Zabbix_Server_IP}'' /etc/zabbix/zabbix_agentd.conf
sed -i '/^Hostname=/c #Hostname=' /etc/zabbix/zabbix_agentd.conf
#sed -i '/^Hostname=/c Hostname='${Zabbix_Agent_IP}'' /etc/zabbix/zabbix_agentd.conf
}
if [ -e /etc/redhat-release ];then
rpm -qa | grep zabbix-agent
if [ $? -ne 0 ];then
rpm -vih /usr/local/zabbix_files/zabbix-agent-4.4.10-1.el7.x86_64.rpm
configure
echo 'Timeout=20' >> /etc/zabbix/zabbix_agentd.conf
else
configure
fi
else
dpkg -l | grep zabbix-agent
if [ $? -ne 0 ];then
dpkg -i /usr/local/zabbix_files/zabbix-agent_4.4.10-1+focal_amd64.deb
configure
echo 'Timeout=20' >> /etc/zabbix/zabbix_agentd.conf
else
configure
fi
fi
六、自定义监控项
以下主要用了低级自动发现(LLD),它提供了一种在计算机上为不同实体自动创建监控项,触发器和图形的方法。
详情请阅读官方文档:https://www.zabbix.com/documentation/4.0/zh/manual/discovery/low_level_discovery
1、nvme自动发现
因为生产环境机器的nvme盘,有时候会发生掉盘,公司需求对nvme盘进行存活性探测。
前端配置:
创建模板→创建应用集→创建发现规则:

创建监控项原型:
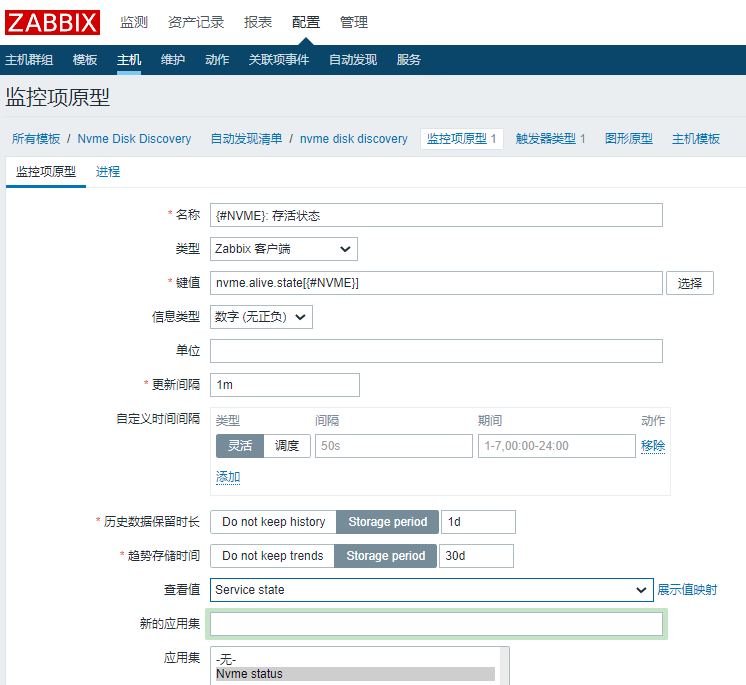
创建触发器:

playbook内容:
[root@zabbix ansible]# tree roles/nvme-discovery/
roles/nvme-discovery/
├── files
│ ├── nvme_discovery.sh
│ ├── nvme_disk_discovery.conf
│ └── nvme_state.sh
├── handlers
│ └── main.yaml
└── tasks
└── main.yaml
[root@zabbix ansible]# cat roles/nvme-discovery/tasks/main.yaml
- name: push nvme disk discovery scripts
copy:
src: "{{ item.src }}"
dest: "{{ item.dest }}"
mode: "{{ item.mode }}"
with_items:
- { src: nvme_discovery.sh , dest: /etc/zabbix/scripts/ , mode: "755" }
- { src: nvme_state.sh , dest: /etc/zabbix/scripts/ , mode: "755" }
- { src: nvme_disk_discovery.conf , dest: /etc/zabbix/zabbix_agentd.d/ , mode: "644" }
notify: restart zabbix-agent
[root@zabbix ansible]# cat roles/nvme-discovery/handlers/main.yaml
- name: restart zabbix-agent
systemd:
name: zabbix-agent
state: restarted
enabled: yes脚本内容(输出json格式的方法比较low,可以用jq工具或者python写吧):
[root@zabbix ansible]# cat roles/nvme-discovery/files/nvme_discovery.sh
#!/bin/bash
NVME=(`lsblk | grep '^nvme' | awk '{print $1}'`)
LENGTH=${#NVME[*]}
printf "{\n"
printf '\t'"\"data\":["
for ((i=0;i<$LENGTH;i++))
do
printf '\n\t\t{'
printf "\"{#NVME}\":\"${NVME[$i]}\"}"
if [ $i -lt $[$LENGTH-1] ];then
printf ','
fi
done
printf "\n\t]\n"
printf "}\n"
[root@zabbix ansible]# cat roles/nvme-discovery/files/nvme_state.sh
#!/bin/bash
if [ -z $1 ];then
exit
else
cat /proc/diskstats | grep $1 >> /dev/null
if [ $? -eq 0 ];then
echo "1"
else
echo "0"
fi
fi
[root@zabbix ansible]# cat roles/nvme-discovery/files/nvme_disk_discovery.conf
UserParameter=nvme.discovery,/etc/zabbix/scripts/nvme_discovery.sh
UserParameter=nvme.alive.state[*],/etc/zabbix/scripts/nvme_state.sh $1
2、显卡驱动检测
因为生产环境机器的显卡驱动,有时候会发生异常,公司需求对服务器的显卡驱动进行监控。
前端配置:
创建模板→创建应用集→创建监控项:
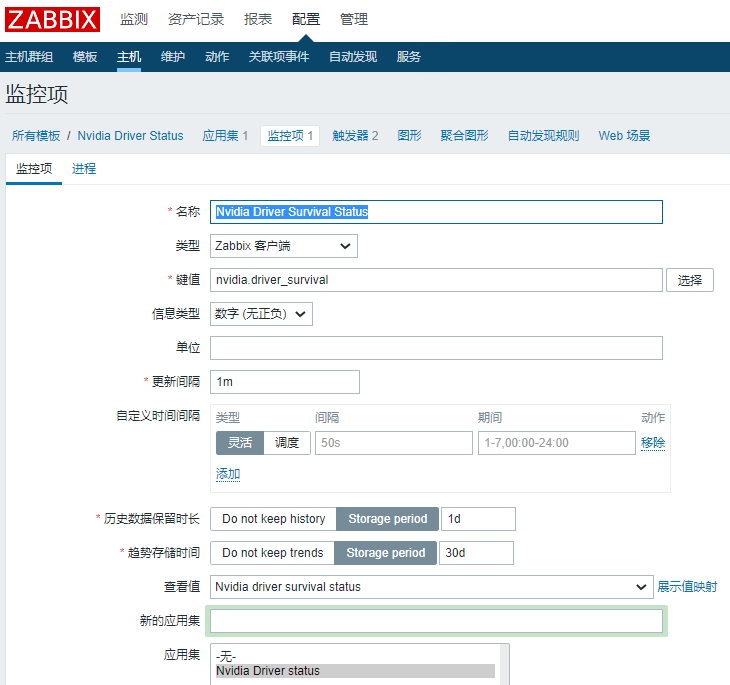
再进行上面一步之前先创建一个值映射,管理→一般→值映射→创建值映射:

创建触发器:
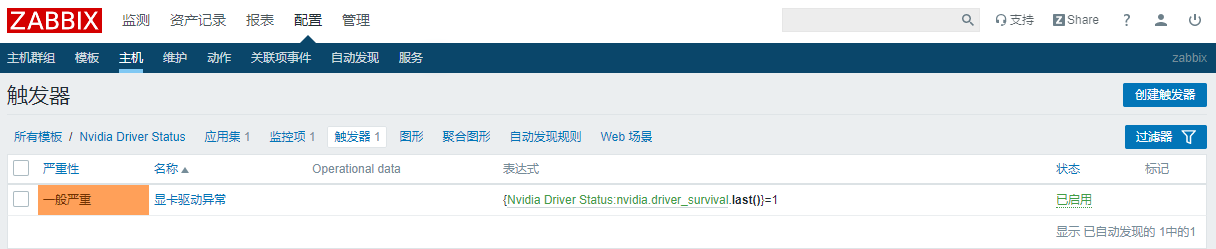
playbook内容:
[root@zabbix ansible]# tree roles/nvidia-driver-survival/
roles/nvidia-driver-survival/
├── files
│ ├── nvidia-driver-survival.conf
│ └── nvidia-driver-survival.sh
├── handlers
│ └── main.yaml
└── tasks
└── main.yaml
[root@zabbix ansible]# cat roles/nvidia-driver-survival/tasks/main.yaml
- name: push nvidia-driver-survival scripts and conf
copy:
src: "{{ item.src }}"
dest: "{{ item.dest }}"
mode: "{{ item.mode }}"
with_items:
- { src: nvidia-driver-survival.sh , dest: /etc/zabbix/scripts/ , mode: "755" }
- { src: nvidia-driver-survival.conf , dest: /etc/zabbix/zabbix_agentd.d/ , mode: "644" }
notify: restart zabbix-agent
[root@zabbix ansible]# cat roles/nvidia-driver-survival/handlers/main.yaml
- name: restart zabbix-agent
systemd:
name: zabbix-agent
state: restarted
enabled: yes脚本内容:
[root@zabbix ansible]# cat roles/nvidia-driver-survival/files/nvidia-driver-survival.sh
#!/bin/bash
lspci | grep -i 'vga' | grep -i 'nvidia' >> /dev/null
if [ $? -eq 0 ];then
type nvidia-smi &>> /dev/null
if [ $? -ne 0 ];then
echo "3"
else
nvidia-smi &>> /dev/null
if [ $? -eq 0 ];then
echo "0"
else
echo "1"
fi
fi
else
echo "2"
fi
[root@zabbix ansible]# cat roles/nvidia-driver-survival/files/nvidia-driver-survival.conf
UserParameter=nvidia.driver_survival,/etc/zabbix/scripts/nvidia-driver-survival.sh
3、gpu自动发现
监控gpu的各种信息,主要参考:https://blog.csdn.net/zxycyj1989/article/details/108650210
前端配置:
创建模板→创建发现规则:
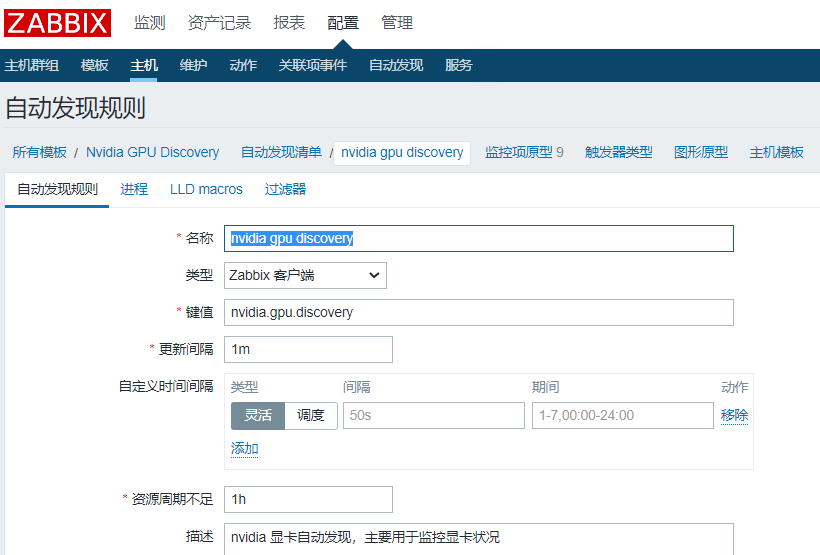
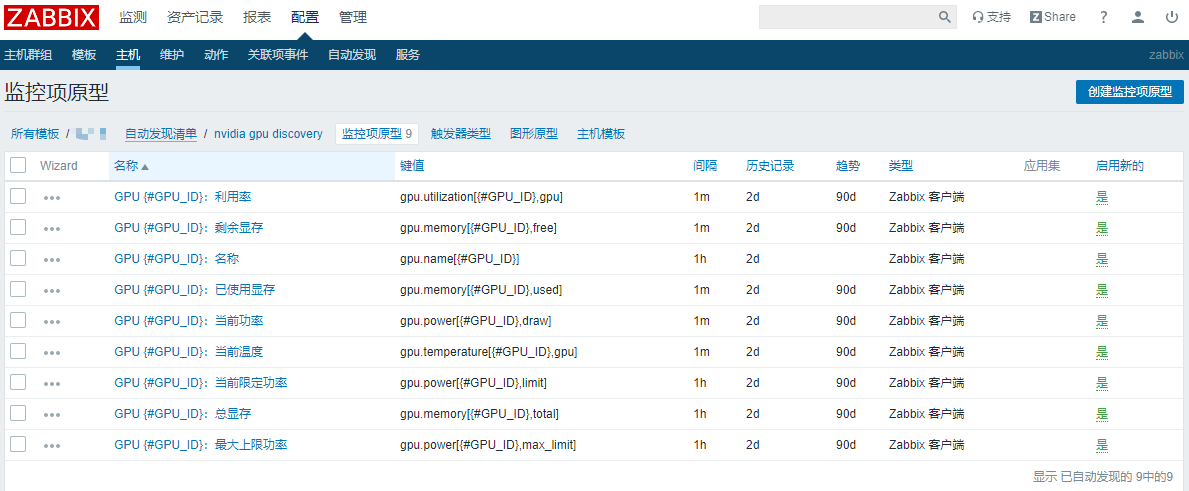
创建监控项原型:

按照以上依次创建以下监控项原型:(根据实际情况进行改动)
playbook内容:
[root@zabbix ansible]# tree roles/nvidia-gpu-discovery/
roles/nvidia-gpu-discovery/
├── files
│ ├── nvidia_gpu_discovery.conf
│ └── nvidia_gpu_discovery.sh
├── handlers
│ └── main.yaml
└── tasks
└── main.yaml
[root@zabbix ansible]# cat roles/nvidia-gpu-discovery/tasks/main.yaml
- name: push nvidia gpu discovery scripts and conf
copy:
src: "{{ item.src }}"
dest: "{{ item.dest }}"
mode: "{{ item.mode }}"
with_items:
- { src: nvidia_gpu_discovery.sh , dest: /etc/zabbix/scripts/ , mode: "755" }
- { src: nvidia_gpu_discovery.conf , dest: /etc/zabbix/zabbix_agentd.d/ , mode: "644" }
notify: restart zabbix-agent
[root@zabbix ansible]# cat roles/nvidia-gpu-discovery/handlers/main.yaml
- name: restart zabbix-agent
systemd:
name: zabbix-agent
state: restarted
enabled: yes脚本内容:
[root@zabbix ansible]# cat roles/nvidia-gpu-discovery/files/nvidia_gpu_discovery.sh
#!/bin/bash
nvidia-smi &>> /dev/null
if [ $? -ne 0 ];then
printf "{\n"
printf '\t'"\"data\":["
printf "\n\t]\n"
printf "}\n"
else
GPUS=(`nvidia-smi -L | awk -F ' |:' '{print $2}'`)
LENGTH=${#GPUS[*]}
printf "{\n"
printf '\t'"\"data\":["
for ((i=0;i<$LENGTH;i++))
do
printf '\n\t\t{'
printf "\"{#GPU_ID}\":\"${GPUS[$i]}\"}"
if [ $i -lt $[$LENGTH-1] ];then
printf ','
fi
done
printf "\n\t]\n"
printf "}\n"
fi
[root@zabbix ansible]# cat roles/nvidia-gpu-discovery/files/nvidia_gpu_discovery.conf
UserParameter=nvidia.gpu.discovery,/etc/zabbix/scripts/nvidia_gpu_discovery.sh
UserParameter=gpu.name[*],nvidia-smi -i $1 --query-gpu=name --format=csv,noheader,nounits
UserParameter=gpu.utilization[*],nvidia-smi -i $1 --query-gpu=utilization.$2 --format=csv,noheader,nounits
UserParameter=gpu.memory[*],nvidia-smi -i $1 --query-gpu=memory.$2 --format=csv,noheader,nounits
UserParameter=gpu.power[*],nvidia-smi -i $1 --query-gpu=power.$2 --format=csv,noheader,nounits
UserParameter=gpu.temperature[*],nvidia-smi -i $1 --query-gpu=temperature.$2 --format=csv,noheader,nounits
4、进程监控
前端配置:
创建模板→创建应用集→创建监控项:

创建触发器:

playbook内容:
[root@zabbix ansible]# tree roles/lotus-alive-state/
roles/lotus-alive-state/
├── files
│ ├── lo-alive-state.sh
│ └── lotus-alive-state.conf
├── handlers
│ └── main.yaml
└── tasks
└── main.yaml
[root@zabbix ansible]# cat roles/lotus-alive-state/tasks/main.yaml
- name: push lotus alive state scripts and conf
copy:
src: "{{ item.src }}"
dest: "{{ item.dest }}"
mode: "{{ item.mode }}"
with_items:
- { src: lo-alive-state.sh , dest: /etc/zabbix/scripts/ , mode: "755" }
- { src: lotus-alive-state.conf , dest: /etc/zabbix/zabbix_agentd.d/ , mode: "644" }
notify: restart zabbix-agent
[root@zabbix ansible]# cat roles/lotus-alive-state/handlers/main.yaml
- name: restart zabbix-agent
systemd:
name: zabbix-agent
state: restarted
enabled: yes脚本内容:
[root@zabbix ansible]# cat roles/lotus-alive-state/files/lo-alive-state.sh
#!/bin/bash
ps -ef | grep lotus | grep -v grep &>> /dev/null
if [ $? -eq 0 ];then
echo "1"
else
echo "0"
fi
[root@zabbix ansible]# cat roles/lotus-alive-state/files/lotus-alive-state.conf
UserParameter=lotus.alive.state,/etc/zabbix/scripts/lo-alive-state.sh
5、分布式存储集群使用容量监控
公司分布式存储集群(ceph)由 xsky 部署,他们有一整套完整的监控,我们这边现只需要监控每套分布式存储集群使用容量即可。
前端配置:
创建模板→创建应用集→创建监控项:

创建触发器:

playbook内容:
[root@zabbix ansible]# tree roles/xsky-cluster-space/
roles/xsky-cluster-space/
├── files
│ ├── xsky-disk-space.conf
│ └── xsky-disk-space.sh
├── handlers
│ └── main.yaml
└── tasks
└── main.yaml
[root@zabbix ansible]# cat roles/xsky-cluster-space/tasks/main.yaml
- name: create usage.txt
file:
path: /etc/zabbix/scripts/usage.txt
owner: zabbix
group: zabbix
state: touch
- name: push xsky disk space scripts and conf
copy:
src: "{{ item.src }}"
dest: "{{ item.dest }}"
mode: "{{ item.mode }}"
with_items:
- { src: xsky-disk-space.sh , dest: /etc/zabbix/scripts/ , mode: "755" }
- { src: xsky-disk-space.conf , dest: /etc/zabbix/zabbix_agentd.d/ , mode: "644" }
notify: restart zabbix-agent
[root@zabbix ansible]# cat roles/xsky-cluster-space/handlers/main.yaml
- name: restart zabbix-agent
systemd:
name: zabbix-agent
state: restarted
enabled: yes脚本内容:
[root@zabbix ansible]# cat roles/xsky-cluster-space/files/xsky-disk-space.sh
#!/bin/bash
#Usage=$(ceph -s | awk '/usage/{print $2/$(NF-1)*100}')
Usage=$(ceph -s | awk '/usage/{print (1-$(NF-3)/$(NF-1))*100}')
echo $Usage > /etc/zabbix/scripts/usage.txt
chown zabbix.zabbix /etc/zabbix/scripts/usage.txt
[root@zabbix ansible]# cat roles/xsky-cluster-space/files/xsky-disk-space.conf
UserParameter=xsky.cluster.space_sh,/etc/zabbix/scripts/xsky-disk-space.sh
UserParameter=xsky.cluster.space,cat /etc/zabbix/scripts/usage.txt
七、钉钉报警
参考:https://www.cnblogs.com/yanjieli/p/10848330.html
先在钉钉群里创建好机器人,关键字设置为:报警。
钉钉报警脚本:
[root@zabbix ~]# cat /etc/zabbix/zabbix_server.conf | grep ^AlertScriptsPath
AlertScriptsPath=/usr/lib/zabbix/alertscripts
[root@zabbix ~]# cd /usr/lib/zabbix/alertscripts/
[root@zabbix alertscripts]# cat dingding.py
#!/usr/bin/env python
#coding:utf-8
#zabbix dingding告警
import requests,json,sys,os,datetime
webhook="机器人的webhook地址"
user=sys.argv[1]
text=sys.argv[3]
data={
"msgtype": "text",
"text": {
"content": text
},
"at": {
"atMobiles": [
user
],
"isAtAll": False
}
}
headers = {'Content-Type': 'application/json'}
x=requests.post(url=webhook,data=json.dumps(data),headers=headers)
[root@zabbix alertscripts]# chmod +x dingding.py脚本测试:
[root@zabbix alertscripts]# yum install python-pip
[root@zabbix alertscripts]# pip install requests
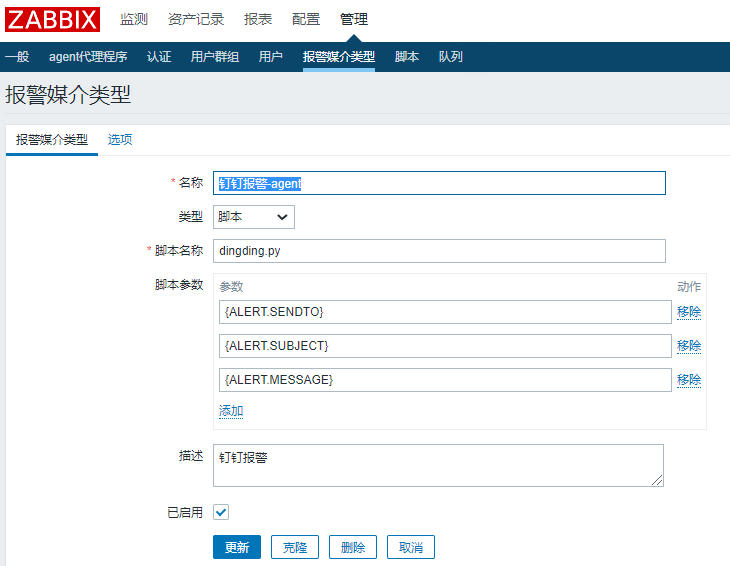
[root@zabbix alertscripts]# ./dingding.py test test "钉钉报警测试"前端配置:
管理→报警媒介类型→创建媒体类型:
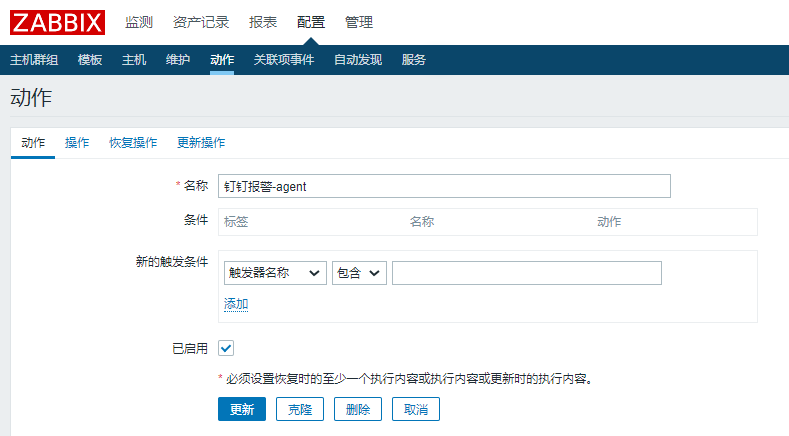
配置→动作→创建动作(事件源选择触发器):
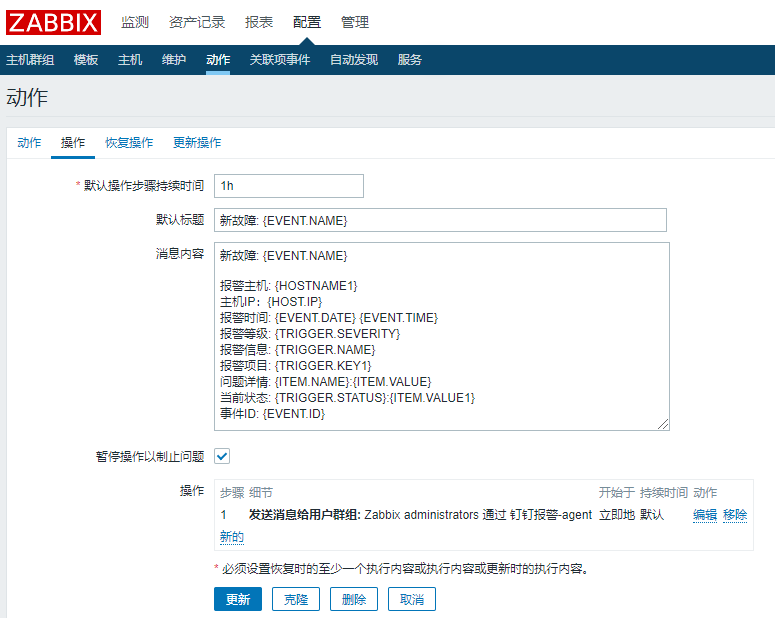
报警消息内容:
新故障: {EVENT.NAME}
报警主机: {HOST.NAME}
主机IP:{HOST.IP}
报警时间: {EVENT.DATE} {EVENT.TIME}
报警等级: {TRIGGER.SEVERITY}
报警信息: {TRIGGER.NAME}
报警项目: {TRIGGER.KEY1}
问题详情: {ITEM.NAME}:{ITEM.VALUE}
当前状态: {TRIGGER.STATUS}:{ITEM.VALUE1}
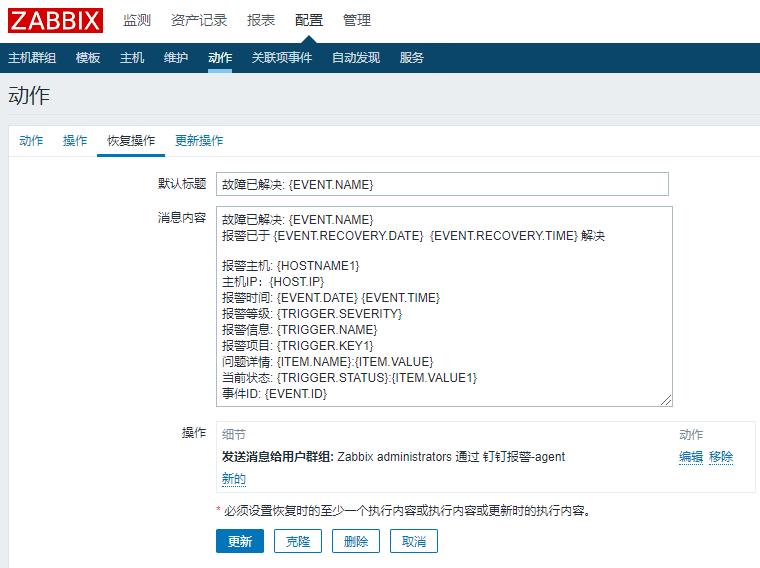
事件ID: {EVENT.ID}恢复消息内容:
故障已解决: {EVENT.NAME}
报警已于 {EVENT.RECOVERY.DATE} {EVENT.RECOVERY.TIME} 解决
报警主机: {HOST.NAME}
主机IP:{HOST.IP}
报警时间: {EVENT.DATE} {EVENT.TIME}
报警等级: {TRIGGER.SEVERITY}
报警信息: {TRIGGER.NAME}
报警项目: {TRIGGER.KEY1}
问题详情: {ITEM.NAME}:{ITEM.VALUE}
当前状态: {TRIGGER.STATUS}:{ITEM.VALUE1}
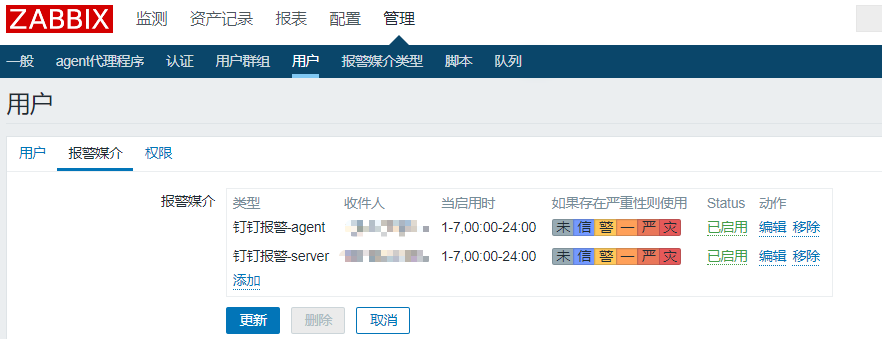
事件ID: {EVENT.ID}给用户设置报警媒介:(收件人为钉钉群里任一群员的电话号码)
八、Grafana
部署:
docker run --restart always -d -p 3000:3000 -e "GF_INSTALL_PLUGINS=alexanderzobnin-zabbix-app" grafana/grafana自定义仪表盘(自己画的比较丑):点击下载
九、优化
zabbix server 优化,以下配置可能不是适合你的环境,请根据实际情况调整以下参数,结合线程和缓存的使用情况(可以在web界面观测)去对应调整。
StartPollers=75
StartPreprocessors=25
StartPollersUnreachable=10
StartTrappers=25
StartPingers=25
StartDiscoverers=10
CacheSize=2G
StartDBSyncers=75
HistoryCacheSize=500M
HistoryIndexCacheSize=500M
TrendCacheSize=500M
ValueCacheSize=500M
Timeout=20
StartLLDProcessors=50mysql 数据库优化:
[root@zabbix ~]# cat /etc/my.cnf
[mysqld]
user=mysql
basedir=/home/mysql/app/mysql
datadir=/home/mysql/data
socket=/var/lib/mysql/mysql.sock
log-error=/var/log/mysql/mysql.err
max_connections=1024
back_log=1024
key_buffer_size=16M
query_cache_size=64M
query_cache_type=1
query_cache_limit=50M
sort_buffer_size=2M
max_allowed_packet=32M
join_buffer_size=2M
innodb_buffer_pool_size=10G
innodb_log_buffer_size=32M
innodb_log_file_size=128M
innodb_log_files_in_group=3
read_buffer_size=2M
read_rnd_buffer_size=2M
[client]
socket=/var/lib/mysql/mysql.sockphp 内存分配调整:
# 修改 php.ini 文件中的 memory_limit (-1表示不限制):
# php是集成到apache中,所以要到httpd服务的配置文件中修改
[root@zabbix /]# vim /etc/httpd/conf.d/zabbix.conf
......
php_value memory_limit 1G
......
[root@zabbix ~]# systemctl restart httpd